
11:34 a.m.
Again Fedora 22 Xfce.
It seems Evince lacks being able to copy an image out of a pdf so I can
paste said image into a presentation. Select text seems to be the only
option.
It was sad when we lost Acrobat reader for Linux.
What other tool can read in pdfs and provide selecting an image (e.g. a
figure in an IEEE standard) that I can then copy over to Libre Office?
thanks

11:51 a.m.
Am 09.06.2016 um 18:34 schrieb Robert Moskowitz:
Again Fedora 22 Xfce.
It seems Evince lacks being able to copy an image out of a pdf so I
can paste said image into a presentation. Select text seems to be the
only option.
It was sad when we lost Acrobat reader for Linux.
What other tool can read in pdfs and provide selecting an image (e.g.
a figure in an IEEE standard) that I can then copy over to Libre Office?
Okular seems to be able to accomplish waht you want to do (right click
on image, copy etc.).
Klaus
12:20 p.m.
On 06/09/2016 12:51 PM, Klaus-Peter Schrage wrote:
Am 09.06.2016 um 18:34 schrieb Robert Moskowitz:
> Again Fedora 22 Xfce.
>
> It seems Evince lacks being able to copy an image out of a pdf so I
> can paste said image into a presentation. Select text seems to be
> the only option.
>
>
> It was sad when we lost Acrobat reader for Linux.
>
>
> What other tool can read in pdfs and provide selecting an image (e.g.
> a figure in an IEEE standard) that I can then copy over to Libre Office?
Okular seems to be able to accomplish waht you want to do (right click
on image, copy etc.).
Klaus
Thanks. Got it and working well.
12:55 p.m.
On 06/09/2016 01:38 PM, Samuel Sieb wrote:
On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
> What other tool can read in pdfs and provide selecting an image (e.g. a
> figure in an IEEE standard) that I can then copy over to Libre Office?
>
Why don't you just use LibreOffice to open the pdf?
When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only a
142pg document.

1:01 p.m.
On 06/09/2016 10:55 AM, Robert Moskowitz wrote:
On 06/09/2016 01:38 PM, Samuel Sieb wrote:
> On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
>> What other tool can read in pdfs and provide selecting an image (e.g. a
>> figure in an IEEE standard) that I can then copy over to Libre Office?
>>
> Why don't you just use LibreOffice to open the pdf?
When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only a
142pg document.
Ok, I've never tried opening one that big. And since that file is not
publicly available, I can't test it.
1:11 p.m.
On 06/09/2016 02:01 PM, Samuel Sieb wrote:
On 06/09/2016 10:55 AM, Robert Moskowitz wrote:
> On 06/09/2016 01:38 PM, Samuel Sieb wrote:
>> On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
>>> What other tool can read in pdfs and provide selecting an image
>>> (e.g. a
>>> figure in an IEEE standard) that I can then copy over to Libre Office?
>>>
>> Why don't you just use LibreOffice to open the pdf?
>
> When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only a
> 142pg document.
>
Ok, I've never tried opening one that big. And since that file is not
publicly available, I can't test it.
http://standards.ieee.org/getieee802/download/802.1AE-2006.pdf
All 802 standards are available free 6 months after publication. We 802
attendees pay the IEEE for this in our conference attendance fee.
see:
http://standards.ieee.org/about/get/

2:25 p.m.
On Thu, Jun 09, 2016 at 02:11:26PM -0400, Robert Moskowitz wrote:
On 06/09/2016 02:01 PM, Samuel Sieb wrote:
>On 06/09/2016 10:55 AM, Robert Moskowitz wrote:
>>On 06/09/2016 01:38 PM, Samuel Sieb wrote:
>>>On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
>>>>What other tool can read in pdfs and provide selecting an
>>>>image (e.g. a
>>>>figure in an IEEE standard) that I can then copy over to Libre Office?
>>>>
>>>Why don't you just use LibreOffice to open the pdf?
>>
>>When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only a
>>142pg document.
>>
>Ok, I've never tried opening one that big. And since that file is
>not publicly available, I can't test it.
http://standards.ieee.org/getieee802/download/802.1AE-2006.pdf
All 802 standards are available free 6 months after publication. We
802 attendees pay the IEEE for this in our conference attendance
fee.
see:
http://standards.ieee.org/about/get/
you can use pdfseparate to extract the page you're interested int,
then pdfimages to get the images on that page.
with the file you point to, for example, the image from page 86 can
be extracted like this:
pdfseparate -f 86 -l 86 8*pdf fred
pdfimages -f 1 -l 1 -png fred foo-%d
which dumps page 86 to a file named fred (I know, it should be fred.pdf)
then grabs the images from that page, creating .png file(s) named foo-<number>
all this takes only a moment. or less.
Fred
--
---- Fred Smith -- fredex(a)fcshome.stoneham.ma.us ----------------------------
Do you not know? Have you not heard?
The LORD is the everlasting God, the Creator of the ends of the earth.
He will not grow tired or weary, and his understanding no one can fathom.
----------------------------- Isaiah 40:28 (niv) -----------------------------
3:04 p.m.
On 06/09/2016 03:25 PM, Fred Smith wrote:
On Thu, Jun 09, 2016 at 02:11:26PM -0400, Robert Moskowitz wrote:
>
> On 06/09/2016 02:01 PM, Samuel Sieb wrote:
>> On 06/09/2016 10:55 AM, Robert Moskowitz wrote:
>>> On 06/09/2016 01:38 PM, Samuel Sieb wrote:
>>>> On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
>>>>> What other tool can read in pdfs and provide selecting an
>>>>> image (e.g. a
>>>>> figure in an IEEE standard) that I can then copy over to Libre
Office?
>>>>>
>>>> Why don't you just use LibreOffice to open the pdf?
>>> When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only a
>>> 142pg document.
>>>
>> Ok, I've never tried opening one that big. And since that file is
>> not publicly available, I can't test it.
> http://standards.ieee.org/getieee802/download/802.1AE-2006.pdf
>
> All 802 standards are available free 6 months after publication. We
> 802 attendees pay the IEEE for this in our conference attendance
> fee.
>
> see:
>
> http://standards.ieee.org/about/get/
you can use pdfseparate to extract the page you're interested int,
then pdfimages to get the images on that page.
with the file you point to, for example, the image from page 86 can
be extracted like this:
pdfseparate -f 86 -l 86 8*pdf fred
pdfimages -f 1 -l 1 -png fred foo-%d
which dumps page 86 to a file named fred (I know, it should be fred.pdf)
then grabs the images from that page, creating .png file(s) named foo-<number>
all this takes only a moment. or less.
thanks!
4:23 p.m.
On 06/09/2016 03:25 PM, Fred Smith wrote:
On Thu, Jun 09, 2016 at 02:11:26PM -0400, Robert Moskowitz wrote:
>
> On 06/09/2016 02:01 PM, Samuel Sieb wrote:
>> On 06/09/2016 10:55 AM, Robert Moskowitz wrote:
>>> On 06/09/2016 01:38 PM, Samuel Sieb wrote:
>>>> On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
>>>>> What other tool can read in pdfs and provide selecting an
>>>>> image (e.g. a
>>>>> figure in an IEEE standard) that I can then copy over to Libre
Office?
>>>>>
>>>> Why don't you just use LibreOffice to open the pdf?
>>> When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only a
>>> 142pg document.
>>>
>> Ok, I've never tried opening one that big. And since that file is
>> not publicly available, I can't test it.
> http://standards.ieee.org/getieee802/download/802.1AE-2006.pdf
>
> All 802 standards are available free 6 months after publication. We
> 802 attendees pay the IEEE for this in our conference attendance
> fee.
>
> see:
>
> http://standards.ieee.org/about/get/
you can use pdfseparate to extract the page you're interested int,
then pdfimages to get the images on that page.
with the file you point to, for example, the image from page 86 can
be extracted like this:
pdfseparate -f 86 -l 86 8*pdf fred
pdfimages -f 1 -l 1 -png fred foo-%d
Yes, that gets fig 12-1, but.
I was able to extract pg 39 for fig 7-7 to a file fred.pdf, but the
pdfimages did not create a foo-1 file.
which dumps page 86 to a file named fred (I know, it should be fred.pdf)
then grabs the images from that page, creating .png file(s) named foo-<number>
all this takes only a moment. or less.
Fred
6:56 p.m.
On Thu, Jun 09, 2016 at 05:23:02PM -0400, Robert Moskowitz wrote:
On 06/09/2016 03:25 PM, Fred Smith wrote:
>On Thu, Jun 09, 2016 at 02:11:26PM -0400, Robert Moskowitz wrote:
>>
>>On 06/09/2016 02:01 PM, Samuel Sieb wrote:
>>>On 06/09/2016 10:55 AM, Robert Moskowitz wrote:
>>>>On 06/09/2016 01:38 PM, Samuel Sieb wrote:
>>>>>On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
>>>>>>What other tool can read in pdfs and provide selecting an
>>>>>>image (e.g. a
>>>>>>figure in an IEEE standard) that I can then copy over to Libre
Office?
>>>>>>
>>>>>Why don't you just use LibreOffice to open the pdf?
>>>>When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only a
>>>>142pg document.
>>>>
>>>Ok, I've never tried opening one that big. And since that file is
>>>not publicly available, I can't test it.
>>http://standards.ieee.org/getieee802/download/802.1AE-2006.pdf
>>
>>All 802 standards are available free 6 months after publication. We
>>802 attendees pay the IEEE for this in our conference attendance
>>fee.
>>
>>see:
>>
>>http://standards.ieee.org/about/get/
>you can use pdfseparate to extract the page you're interested int,
>then pdfimages to get the images on that page.
>
>with the file you point to, for example, the image from page 86 can
>be extracted like this:
>
>pdfseparate -f 86 -l 86 8*pdf fred
>pdfimages -f 1 -l 1 -png fred foo-%d
Yes, that gets fig 12-1, but.
I was able to extract pg 39 for fig 7-7 to a file fred.pdf, but the
pdfimages did not create a foo-1 file.
There's something weird about that document, there a number of figures
that do not show up in the pdfimages output. here's what it lists for
the entire document:
page num type width height color comp bpc enc interp object ID x-ppi y-ppi size
ratio
--------------------------------------------------------------------------------------------
1 0 image 459 164 index 1 8 jpx no 2737 0 257 257 9714B
13%
1 1 image 459 164 index 1 8 jpx no 2738 0 257 257 12.9K
18%
1 2 stencil 394 186 - 1 1 ccitt no 2739 0 301 301 436B
4.8%
1 3 stencil 394 184 - 1 1 ccitt no 2740 0 301 300 398B
4.4%
1 4 stencil 387 182 - 1 1 ccitt no 2741 0 301 300 413B
4.7%
1 5 stencil 387 55 - 1 1 ccitt no 2742 0 301 300 61B
2.3%
1 6 stencil 387 116 - 1 1 ccitt no 2743 0 301 300 139B
2.5%
1 7 stencil 387 256 - 1 1 ccitt no 2744 0 301 301 515B
4.2%
1 8 stencil 387 205 - 1 1 ccitt no 2745 0 301 300 220B
2.2%
1 9 stencil 96 53 - 1 1 ccitt no 2734 0 301 301 65B
10%
1 10 stencil 96 63 - 1 1 ccitt no 2735 0 301 300 118B
16%
52 11 image 670 104 index 1 8 jpx no 155 0 179 150 7267B
10%
86 12 image 675 407 index 1 8 jpx no 259 0 120 120 41.3K
15%
so either pdfimages is busted, or some of the figures in that document
are stored/created in some unusual way. I don't know enough about PDF
internals to have a clue.
Sorry I can't be of more help.
Fred
--
---- Fred Smith -- fredex(a)fcshome.stoneham.ma.us -----------------------------
The Lord detests the way of the wicked
but he loves those who pursue righteousness.
----------------------------- Proverbs 15:9 (niv) -----------------------------
7:08 p.m.
On Thu, Jun 09, 2016 at 07:56:58PM -0400, Fred Smith wrote:
On Thu, Jun 09, 2016 at 05:23:02PM -0400, Robert Moskowitz wrote:
>
>
> On 06/09/2016 03:25 PM, Fred Smith wrote:
> >On Thu, Jun 09, 2016 at 02:11:26PM -0400, Robert Moskowitz wrote:
> >>
> >>On 06/09/2016 02:01 PM, Samuel Sieb wrote:
> >>>On 06/09/2016 10:55 AM, Robert Moskowitz wrote:
> >>>>On 06/09/2016 01:38 PM, Samuel Sieb wrote:
> >>>>>On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
> >>>>>>What other tool can read in pdfs and provide selecting an
> >>>>>>image (e.g. a
> >>>>>>figure in an IEEE standard) that I can then copy over to
Libre Office?
> >>>>>>
> >>>>>Why don't you just use LibreOffice to open the pdf?
> >>>>When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only
a
> >>>>142pg document.
> >>>>
> >>>Ok, I've never tried opening one that big. And since that file is
> >>>not publicly available, I can't test it.
> >>http://standards.ieee.org/getieee802/download/802.1AE-2006.pdf
> >>
> >>All 802 standards are available free 6 months after publication. We
> >>802 attendees pay the IEEE for this in our conference attendance
> >>fee.
> >>
> >>see:
> >>
> >>http://standards.ieee.org/about/get/
> >you can use pdfseparate to extract the page you're interested int,
> >then pdfimages to get the images on that page.
> >
> >with the file you point to, for example, the image from page 86 can
> >be extracted like this:
> >
> >pdfseparate -f 86 -l 86 8*pdf fred
> >pdfimages -f 1 -l 1 -png fred foo-%d
>
> Yes, that gets fig 12-1, but.
>
> I was able to extract pg 39 for fig 7-7 to a file fred.pdf, but the
> pdfimages did not create a foo-1 file.
There's something weird about that document, there a number of figures
that do not show up in the pdfimages output. here's what it lists for
the entire document:
page num type width height color comp bpc enc interp object ID x-ppi y-ppi size
ratio
--------------------------------------------------------------------------------------------
1 0 image 459 164 index 1 8 jpx no 2737 0 257 257 9714B
13%
1 1 image 459 164 index 1 8 jpx no 2738 0 257 257 12.9K
18%
1 2 stencil 394 186 - 1 1 ccitt no 2739 0 301 301 436B
4.8%
1 3 stencil 394 184 - 1 1 ccitt no 2740 0 301 300 398B
4.4%
1 4 stencil 387 182 - 1 1 ccitt no 2741 0 301 300 413B
4.7%
1 5 stencil 387 55 - 1 1 ccitt no 2742 0 301 300 61B
2.3%
1 6 stencil 387 116 - 1 1 ccitt no 2743 0 301 300 139B
2.5%
1 7 stencil 387 256 - 1 1 ccitt no 2744 0 301 301 515B
4.2%
1 8 stencil 387 205 - 1 1 ccitt no 2745 0 301 300 220B
2.2%
1 9 stencil 96 53 - 1 1 ccitt no 2734 0 301 301 65B
10%
1 10 stencil 96 63 - 1 1 ccitt no 2735 0 301 300 118B
16%
52 11 image 670 104 index 1 8 jpx no 155 0 179 150 7267B
10%
86 12 image 675 407 index 1 8 jpx no 259 0 120 120 41.3K
15%
so either pdfimages is busted, or some of the figures in that document
are stored/created in some unusual way. I don't know enough about PDF
internals to have a clue.
Sorry I can't be of more help.
Fred
Oh, some more information:
if I open that document with evince, and scroll to figure 12-1, I can
right-click the figure and one of the options is "save image".
if I scroll to fig 7-7 (or pretty much any of the figures in there) and
right-click the image, I DO NOT get that option.
more evidence that they were created/embedded differently.
Fred
--
---- Fred Smith -- fredex(a)fcshome.stoneham.ma.us -----------------------------
"Not everyone who says to me, 'Lord, Lord,' will enter the kingdom of
heaven, but only he who does the will of my Father who is in heaven."
------------------------------ Matthew 7:21 (niv) -----------------------------
7:37 p.m.
On 06/09/2016 05:08 PM, Fred Smith wrote:
if I open that document with evince, and scroll to figure 12-1, I
can
right-click the figure and one of the options is "save image".
if I scroll to fig 7-7 (or pretty much any of the figures in there) and
right-click the image, I DO NOT get that option.
more evidence that they were created/embedded differently.
They're probably drawings, not pixel-based images. Unless there's some
way to mark an embedded drawing, it's pretty hard to distinguish a
vector image from any other part of the document since it's all Postscript.
8:14 p.m.
On 06/09/2016 08:37 PM, Samuel Sieb wrote:
On 06/09/2016 05:08 PM, Fred Smith wrote:
> if I open that document with evince, and scroll to figure 12-1, I can
> right-click the figure and one of the options is "save image".
>
> if I scroll to fig 7-7 (or pretty much any of the figures in there) and
> right-click the image, I DO NOT get that option.
>
> more evidence that they were created/embedded differently.
>
They're probably drawings, not pixel-based images. Unless there's
some way to mark an embedded drawing, it's pretty hard to distinguish
a vector image from any other part of the document since it's all
Postscript.
I would not be surprised if the images that are not accessible are from
Visio, and those that are were jpgs or gifs that one of the contributors
provided that the editor did not bother to convert to Visio.
At least with Okular, I can select a block and make an image to paste
into a presentation. So I will just stay with that method.
An interesting look into pdfs.
3:10 p.m.
On 06/09/2016 11:11 AM, Robert Moskowitz wrote:
On 06/09/2016 02:01 PM, Samuel Sieb wrote:
> On 06/09/2016 10:55 AM, Robert Moskowitz wrote:
>> On 06/09/2016 01:38 PM, Samuel Sieb wrote:
>>> On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
>>>> What other tool can read in pdfs and provide selecting an image
>>>> (e.g. a
>>>> figure in an IEEE standard) that I can then copy over to Libre Office?
>>>>
>>> Why don't you just use LibreOffice to open the pdf?
>>
>> When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only a
>> 142pg document.
>>
> Ok, I've never tried opening one that big. And since that file is not
> publicly available, I can't test it.
http://standards.ieee.org/getieee802/download/802.1AE-2006.pdf
It turns out that page 43 makes LibreOffice very unhappy for some
reason, probably the diagram background. There's an existing similar
bug report at https://bugs.documentfoundation.org/show_bug.cgi?id=42374
which I added a comment to.
3:38 p.m.
On 06/09/2016 04:10 PM, Samuel Sieb wrote:
On 06/09/2016 11:11 AM, Robert Moskowitz wrote:
>
>
> On 06/09/2016 02:01 PM, Samuel Sieb wrote:
>> On 06/09/2016 10:55 AM, Robert Moskowitz wrote:
>>> On 06/09/2016 01:38 PM, Samuel Sieb wrote:
>>>> On 06/09/2016 09:34 AM, Robert Moskowitz wrote:
>>>>> What other tool can read in pdfs and provide selecting an image
>>>>> (e.g. a
>>>>> figure in an IEEE standard) that I can then copy over to Libre
>>>>> Office?
>>>>>
>>>> Why don't you just use LibreOffice to open the pdf?
>>>
>>> When I try opening IEEE 802.1AE-2006 pdf, it hangs. And it is only a
>>> 142pg document.
>>>
>> Ok, I've never tried opening one that big. And since that file is not
>> publicly available, I can't test it.
>
> http://standards.ieee.org/getieee802/download/802.1AE-2006.pdf
>
It turns out that page 43 makes LibreOffice very unhappy for some
reason, probably the diagram background. There's an existing similar
bug report at
https://bugs.documentfoundation.org/show_bug.cgi?id=42374 which I
added a comment to.
And that kind of diagram is very common in 802 standards. IEEE SA has
rules on such things. All documents are in Framemaker and figures and
diagrams in Visio. You REALLY want your workgroup's editor to do the
work in them, and not give them over to SA, say in Word and jpgs, for
them to convert. Unpleasant things have been known to happen. You can
eat up another year fixing them before publishing.
How do I know all that? Look at the list of participants. You will see
me there...
Of course you mean pg 43 of the pdf which is pg 31 of the standard. A
standard issue with 802 standards :)
thanks
12:50 p.m.
On Thu, Jun 09, 2016 at 12:34:59PM -0400, Robert Moskowitz wrote:
Again Fedora 22 Xfce.
It seems Evince lacks being able to copy an image out of a pdf so I
can paste said image into a presentation. Select text seems to be
the only option.
It was sad when we lost Acrobat reader for Linux.
What other tool can read in pdfs and provide selecting an image
(e.g. a figure in an IEEE standard) that I can then copy over to
Libre Office?
pdfimages?
yum whatprovides */pdfimages
poppler-utils-0.26.5-5.el7.x86_64 : Command line utilities for converting PDF
: files
Repo : base
Matched from:
Filename : /usr/bin/pdfimages
poppler-utils-0.26.5-5.el7.x86_64 : Command line utilities for converting PDF
: files
Repo : @cr
Matched from:
Filename : /usr/bin/pdfimages
--
-------------------------------------------------------------------------------
.---- Fred Smith /
( /__ ,__. __ __ / __ : /
/ / / /__) / / /__) .+' Home: fredex(a)fcshome.stoneham.ma.us
/ / (__ (___ (__(_ (___ / :__ 781-438-5471
-------------------------------- Jude 1:24,25 ---------------------------------
12:58 p.m.
On 06/09/2016 01:50 PM, Fred Smith wrote:
On Thu, Jun 09, 2016 at 12:34:59PM -0400, Robert Moskowitz wrote:
> Again Fedora 22 Xfce.
>
> It seems Evince lacks being able to copy an image out of a pdf so I
> can paste said image into a presentation. Select text seems to be
> the only option.
>
>
> It was sad when we lost Acrobat reader for Linux.
>
>
> What other tool can read in pdfs and provide selecting an image
> (e.g. a figure in an IEEE standard) that I can then copy over to
> Libre Office?
pdfimages?
yum whatprovides */pdfimages
poppler-utils-0.26.5-5.el7.x86_64 : Command line utilities for converting PDF
: files
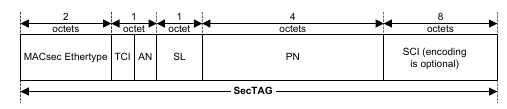
I want to pull out specific figures to include in a presentation. Not
convert the entire pdf to an image.
Like this fig 9-2:
Repo : base
Matched from:
Filename : /usr/bin/pdfimages
poppler-utils-0.26.5-5.el7.x86_64 : Command line utilities for converting PDF
: files
Repo : @cr
Matched from:
Filename : /usr/bin/pdfimages
{kind=link}
3:41 a.m.
Am 09.06.2016 um 19:58 schrieb Robert Moskowitz:
I want to pull out specific figures to include in a presentation. Not
convert the entire pdf to an image.
Like this fig 9-2:
If you really want to pull a vector graphic like this in a clean
way,
you can do it with Inkscape (any other vector editing tool capable of
handling pdf works as well, but I often use this one):
* as Inkscape only seems to be able to open a single pdf page, first
extract the page in question (e. g. page 39) with a tool of your liking
* open page39.pdf in Inkscape
* with the selection tool, draw a rectangle which covers all elements
of your figure
* copy and paste the selection to a new empty drawing
* save as fig9_2.svg or fig9_2.eps
4:42 a.m.
On 06/10/2016 04:41 AM, Klaus-Peter Schrage wrote:
Am 09.06.2016 um 19:58 schrieb Robert Moskowitz:
> I want to pull out specific figures to include in a presentation. Not
> convert the entire pdf to an image.
>
> Like this fig 9-2:
If you really want to pull a vector graphic like this in a clean way,
you can do it with Inkscape (any other vector editing tool capable of
handling pdf works as well, but I often use this one):
* as Inkscape only seems to be able to open a single pdf page, first
extract the page in question (e. g. page 39) with a tool of your
liking
* open page39.pdf in Inkscape
* with the selection tool, draw a rectangle which covers all elements
of your figure
* copy and paste the selection to a new empty drawing
* save as fig9_2.svg or fig9_2.eps
I will look into Inkscape, I see it in the F22 repo. But what is a svg
or eps file? Can they be imported into a Libreoffice presentation? And
then Powerpoint?
Thanks
5:43 a.m.
Am 10.06.2016 um 11:42 schrieb Robert Moskowitz:
On 06/10/2016 04:41 AM, Klaus-Peter Schrage wrote:
> Am 09.06.2016 um 19:58 schrieb Robert Moskowitz:
>
>> I want to pull out specific figures to include in a presentation.
>> Not convert the entire pdf to an image.
>>
>> Like this fig 9-2:
> If you really want to pull a vector graphic like this in a clean way,
> you can do it with Inkscape (any other vector editing tool capable of
> handling pdf works as well, but I often use this one):
>
> * as Inkscape only seems to be able to open a single pdf page, first
> extract the page in question (e. g. page 39) with a tool of your
> liking
> * open page39.pdf in Inkscape
> * with the selection tool, draw a rectangle which covers all elements
> of your figure
> * copy and paste the selection to a new empty drawing
> * save as fig9_2.svg or fig9_2.eps
I will look into Inkscape, I see it in the F22 repo. But what is a
svg or eps file? Can they be imported into a Libreoffice
presentation? And then Powerpoint?
Thanks
They are both vector graphics formats:
https://en.wikipedia.org/wiki/Scalable_Vector_Graphics
https://en.wikipedia.org/wiki/Encapsulated_PostScript
Libreoffice impress can import svg files, but for reasons I dont know,
it doesn't read eps, at least the ones created with Inkscape.
Powerpoint (2010), on the other hand, imports eps, but not svg ...
If you want to try the files, you can download fig 9-2 in eps and svg
format from here:
https://www.dropbox.com/sh/8c1ua34sxv27dth/AACpb_fM3ieiwzvV_OyVxefRa?dl=0
7:43 a.m.
On 06/10/2016 04:41 AM, Klaus-Peter Schrage wrote:
Am 09.06.2016 um 19:58 schrieb Robert Moskowitz:
> I want to pull out specific figures to include in a presentation. Not
> convert the entire pdf to an image.
>
> Like this fig 9-2:
If you really want to pull a vector graphic like this in a clean way,
you can do it with Inkscape (any other vector editing tool capable of
handling pdf works as well, but I often use this one):
* as Inkscape only seems to be able to open a single pdf page, first
extract the page in question (e. g. page 39) with a tool of your
liking
* open page39.pdf in Inkscape
* with the selection tool, draw a rectangle which covers all elements
of your figure
* copy and paste the selection to a new empty drawing
* save as fig9_2.svg or fig9_2.eps
I got it to paste right into LibreOffice Impress. Of course it is the
full graphic with all the elements showing! Not a pixel image when I
use Okular!
thanks

11:41 p.m.
On 06/09/2016 11:34 AM, Robert Moskowitz wrote:
Again Fedora 22 Xfce.
It seems Evince lacks being able to copy an image out of a pdf so I
can paste said image into a presentation. Select text seems to be the
only option.
It was sad when we lost Acrobat reader for Linux.
What other tool can read in pdfs and provide selecting an image (e.g.
a figure in an IEEE standard) that I can then copy over to Libre Office?
thanks
--
users mailing list
users(a)lists.fedoraproject.org
To unsubscribe or change subscription options:
https://lists.fedoraproject.org/admin/lists/users@lists.fedoraproject.org
Fedora Code of Conduct: http://fedoraproject.org/code-of-conduct
Guidelines: http://fedoraproject.org/wiki/Mailing_list_guidelines
Have a question? Ask away: http://ask.fedoraproject.org
I have copied
images--actually whole pages with images--presented on
Master PDF Editor 3--and pasted the whole thing, with the image, into
Libre Office Writer 5.1. So I assume you could just
copy the image. If not, you could edit out the text, I suppose.
--doug

6:40 a.m.
Again Fedora 22 Xfce.
It seems Evince lacks being able to copy an image out of a pdf so I
can
paste said image into a presentation. Select text seems to be the
only
option.
It was sad when we lost Acrobat reader for Linux.
What other tool can read in pdfs and provide selecting an image (e.g.
a
figure in an IEEE standard) that I can then copy over to Libre Office?
thanks
--
I use gimp. You are limited to one page at a time, but it is easy to
select and area and then create the kind of file that you want.
Greg Ennis

9:49 a.m.
Allegedly, on or about 09 June 2016, Robert Moskowitz sent:
What other tool can read in pdfs and provide selecting an image
(e.g.
a figure in an IEEE standard) that I can then copy over to Libre
Office?
Since nobody's suggested it, I'll state a crude workaround:
1. Display the graphic you want to use.
2. Hit the PrintScreen button.
3. Save the file and import it into your office program.
LibreOffice is a bit awful at handling images, though. So, you may want
to size up your initial display to how big you want it, and edit the
saved file in something like GIMP, before importing it into LibreOffice.
--
[tim@localhost ~]$ uname -rsvp
Linux 3.9.10-100.fc17.x86_64 #1 SMP Sun Jul 14 01:31:27 UTC 2013 x86_64
Boilerplate: All mail to my mailbox is automatically deleted, there is
no point trying to privately email me, I only get to see the messages
posted to the mailing list.
Windows, it's enough to make a grown man cry!
2879
days inactive
2883
days old
24 comments
7 participants
participants (7)
-
 Doug
Doug -
 Fred Smith
Fred Smith -
 Gregory P. Ennis
Gregory P. Ennis -
 Klaus-Peter Schrage
Klaus-Peter Schrage -
 Robert Moskowitz
Robert Moskowitz -
 Samuel Sieb
Samuel Sieb -
 Tim
Tim